A long preamble
As a programmer, it's often shocking to me the rift that exists between writing software, and knowing how a computer works. Web developers probably have it the toughest. You can write your React TODO app, and in no time have it effortlessly do dynamic checkboxing galore at the low low cost of thousands of megabytes of memory. And you never have to think about the stupid amount of abstractions that happen under the hood to make this work. The transpiling of Typescript to JavaScript. The JavaScript interpreter building bytecode on the fly. The network protocols defining forms and shapes of data, so that it can be sent, received and parsed by independent participants. The services that the host operating system runs to facilitate all those middle steps. The weaving and bobbing of data between your user space "server" and the OS kernel. The processor threads spawning in and out of existence at the speed of light. It's just insane how much happens under the hood. And all written by humans, by the way.
I have slowly begun to accept that I will never know all of these inner workings and how they function. But my everlasting internal strive for freedom shouts and begs. It wants me to know more, so I can do more. In my vain attempt at achieving ever broader knowledge, I recognise the opportunity to learn to do better at things I am but adequate at. Or, at least such are the delusions of a man, who just wants, nay - needs to always know more.
The Gedankenexperiment
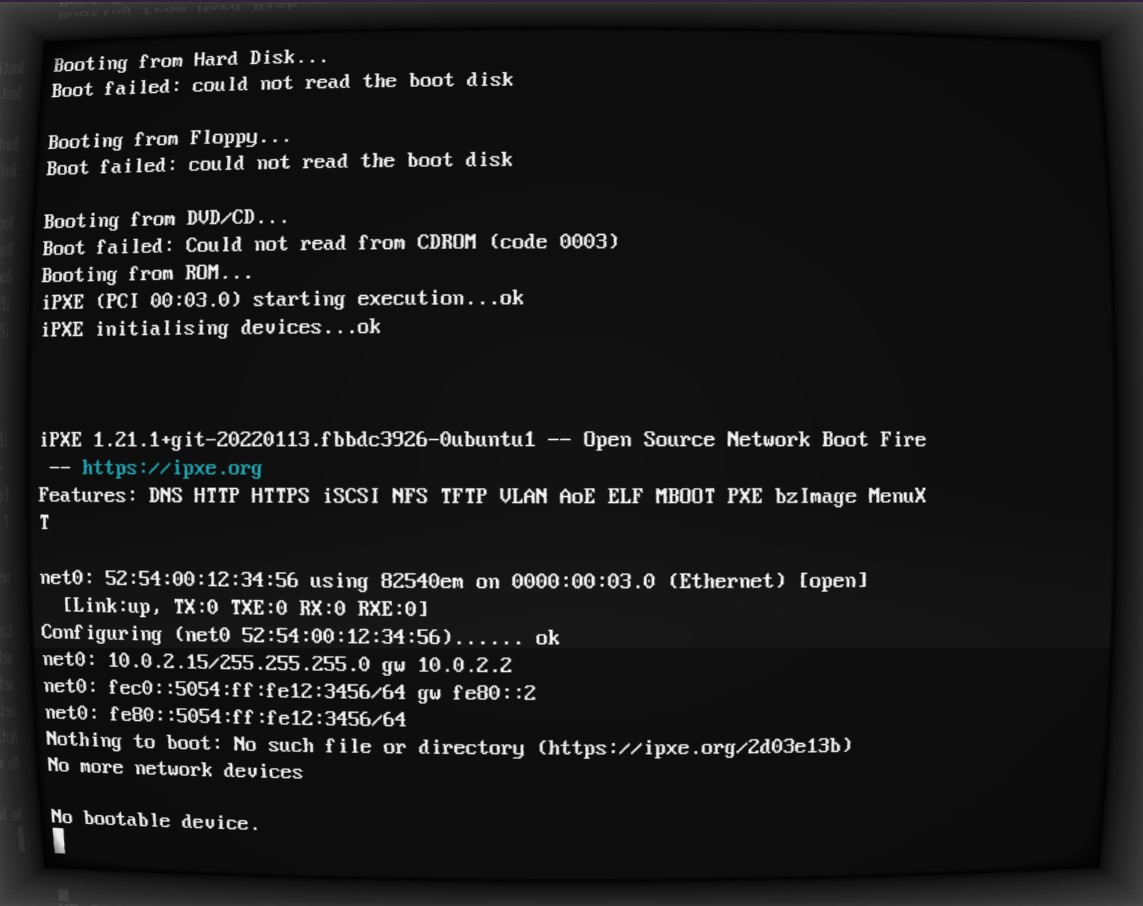
In that vein, I propose a thought experiment. Imagine that, due to circumstances out of the scope of this experiment, you find yourself locked in a basement. You have no wants for food or drink, but you need to communicate with the outside world. You have a PC in the basement. And it has a network cable plugged into it. You try turning the PC on, but all you see is the standard IBM PC BIOS start, and that classic POST check happen, with the ubiquitous high-pitched electronic bing to notify you that all is indeed good. But all is not good. The machine has no operating system, so you can't even check your Twitter, to make yourself feel good for being locked in a basement. All of that raw computing power right there in front of you, and you can't do anything with it!
You look around, and you find also a classic 3.5 inch floppy disk sitting on the desk (no, it's not a 3D-printed save icon), waiting patiently to be inserted into the floppy drive of the (apparently ancient) PC. You recognise the disk. You know it's just short of being empty, apart from something small on the boot sector of it.
A plan is now condensing onto the dimpled glossy surface of your brain like morning dew on motherboards laying in an electronics garbage dump. You need to write an operating system, some network drivers, a client for one of the hundreds of network protocols, and send a message out!
The question posed for the thought experiment is: what is on the floppy disk's boot sector, such that it would allow you to bootstrap the process?
At the end of this preamble, I want to point out that I'm no OS developer, and this is not a series of articles to teach you how to structure and create the next Linux kernel. This is just me playing around, breaking a lot of things, and learning along the way. Take the information here with a grain of salt, and mainly for entertainment purposes. What I'm doing here may seem obvious to you, or just plain boring - or it may be as weirdly magical and thought-provoking as it is for me. In either case, you might find something you enjoy. But you've been forewarned - an OS development course this ain't.
The bootloader
Modern IBM compatible PCs differ from hunks of expensively produced rocks of precious materials in one big way - they tend to have a Basic Input Output System (BIOS) installed on a ROM somewhere on their motherboards. This little program has two main jobs - running a diagnostic Power-On Self-Test (POST), and then giving the control to a user-provided program, which can further utilise the BIOS interrupts if it so desires.
As it can be seen on the screenshot above, the BIOS will look for bootable devices amongst different media such as CD-Roms, hard-drives and floppy drives. What it's looking for in particular is a so-called bootloader program, located on the medium's boot sector. What's a boot sector? Just a piece of memory, which is exactly 512 bytes long, and ends on the magic number 0xAA55. The BIOS will just take these 512 bytes of memory, plop them on memory address 0x7C00, and execute them. From there on, it takes no responsibility for what happens, apart from providing some basic input/output capabilities in the form of so-called BIOS interrupts.
So, our first goal is now becoming clearer. We need to write a program which is up to 512 bytes large, pad the remaining memory with zeroes, and end it with the magic number. Inside of this program, we can make use of BIOS interrupts.
The last thing we need to take into account is how we address memory. This is a huge topic with regards to how it's done in any operating system/hardware combo. For the purposes of this initial step, we can skip the explanations, and just state as a fact, that we will address memory using the so-called "16-bit real mode". So, we can just address anything we want from address 0x0000 to 0xFFFF. And I mean it when I say anything. We can just read and overwrite anything in that range, potentially just breaking stuff along the way.
Well, we've pretty much established the first set of constraints of what needs to happen for our thought experiment. On the floppy disk our past selves have thoughtfully provided for us to use, we need to have a program, which:
- Is no larger than 512 bytes.
- Needs to know it will be put on memory address
0x7C00. - Has to end on the magic number
0xAA55. - Can address memory using 16-bit numbers.
- Can use BIOS interrupts to communicate with hardware.
Wilson
So, let's turn our silicon-rock-of-a-computer into a virtual Wilson. I'm providing the assembly snippet that can make that happen, with comments. I hope those comments make sense, since I will attempt to not explain the code in text too much.
[BITS 16] ; Use 16-bit mode (x86 real mode)
[ORG 0x7C00] ; Origin - BIOS loads boot sector at memory address 0x7C00
start:
; Print 'H'
mov ah, 0x0E ; BIOS teletype output function (INT 10h, AH=0Eh)
mov al, 'H' ; Character to print
int 0x10 ; Call BIOS interrupt to display the character
; Print 'i'
mov ah, 0x0E ; BIOS teletype output function
mov al, 'i' ; Character to print
int 0x10 ; Call BIOS interrupt to display the character
; Infinite loop to prevent the bootloader from proceeding
hang:
jmp hang
; Boot sector signature (must be 0xAA55 for BIOS to recognize it as bootable)
times 510-($-$$) db 0 ; Fill the rest of the boot sector with zeroes
dw 0xAA55 ; Boot sector magic number
I suspect that the only thing which is harder to grasp is the interrupts themselves. They are just another set of magic numbers that point to routines loaded into memory by BIOS itself. There exists a comprehensive list of BIOS interrupts out there, for those curious about them.
As to how I compile this, put it on a floppy and run it in an emulator: you can check my repository on the matter, called zilch. Now, let's see how Wilson is doing.
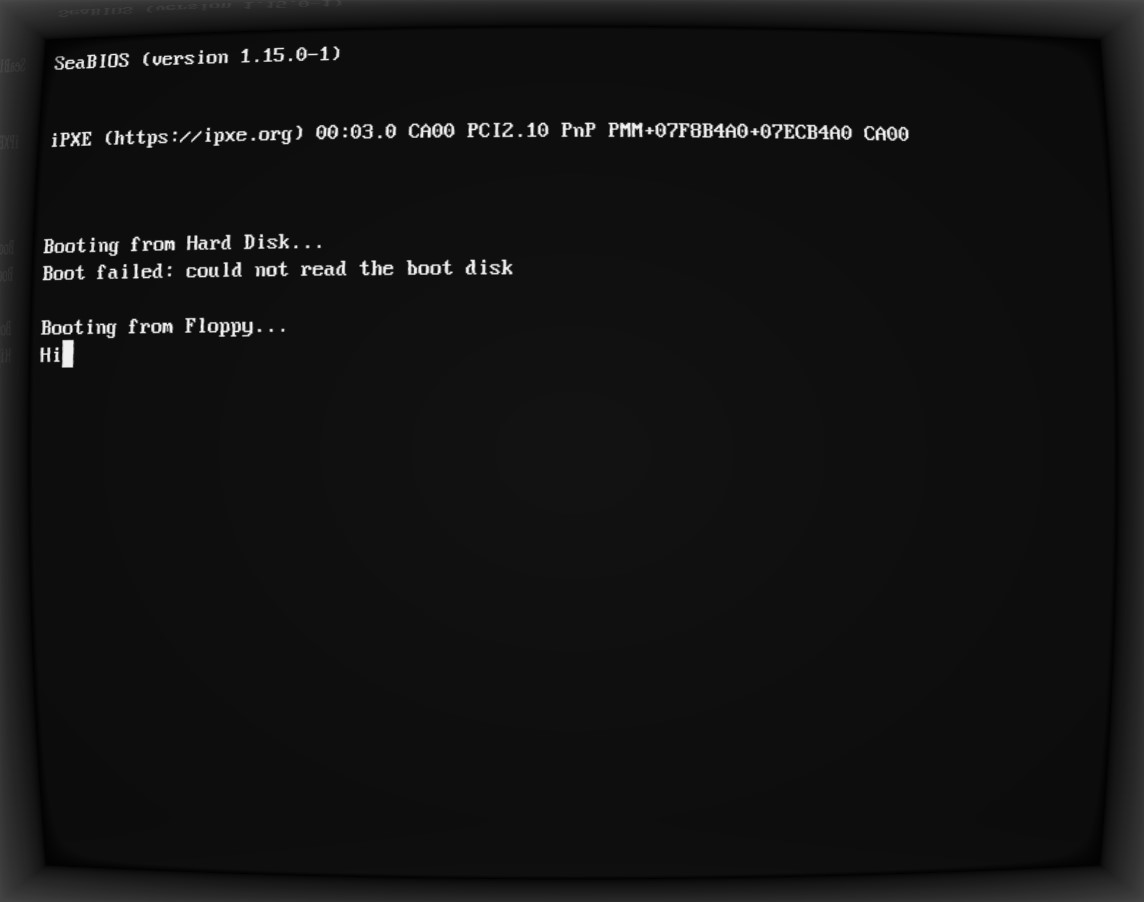
Excellent! The beginnings of a long-lasting friendship, I'd imagine.
The monitor
Now, Wilson is cool and all, but we have to push forward in order to achieve the true objective of our thought experiment. We need to have a program, which would bootstrap our OS-development efforts. If our past selves left a floppy disk with a program that just prints Hi on the screen, I don't think we'd get too far. Or be pleased with ourselves.
What we need is a program, which can receive input from the keyboard, and at some point execute whatever we input. This is called a monitor. Let's start real-simple-like, and define our monitor as such:
- The monitor can read keyboard strokes.
- The input will be called the program.
- The user can input the program using octal code (numbers in base 8 (digits from 0 to 7)).
- The monitor will translate this input into hex (numbers in base 16), so that it can be understood as memory addresses, opcodes, and BIOS interrupts.
- The user won't see what they're typing.
- The user won't be able to edit what they type. If they make a mistake, they need to restart the computer and start from scratch.
- The program will be stored on the boot sector, in the empty space between the end of the monitor, and the magic number
0xAA55. - If the user types anything different from a digit from 0 to 7, the monitor will execute the program that has been input so far.
Point 7 limits the size of our program to . It can be very easily avoided, but let's just keep it for now, as a minimalism thing.
Well, in all honesty, I just described exactly the operation of our little monitor, so let's just see it written in assembly.
[BITS 16]
[ORG 0x7C00] ; BIOS loads the boot sector here
; Main loop
main:
mov si, program ; Initialize pointer to the program array
input_loop:
mov cx, 3 ; Read 3 digits
digit_input:
; Read a character from the keyboard
call getch
sub al, '0' ; Convert ASCII to numerical value
cmp al, 7
ja execute_program ; If input is greater than '7', jump to execute the program
; Multiply the current byte by 8 and add the new digit
mov bl, byte [si]
shl bl, 3
add bl, al
mov byte [si], bl
loop digit_input
; Move to the next byte in the program array
inc si
jmp input_loop
; Execute the program stored in memory
execute_program:
call program
; Infinite loop (halt the CPU)
jmp $
; Function to read a character from the keyboard using BIOS interrupt 0x16
getch:
mov ah, 0x00
int 0x16
ret
; Reserve the remaining space on the boot sector for the program we input
program: times 510-($-$$) db 0
; Boot sector magic number
dw 0xAA55
Again, the only special thing in the code itself is that we use BIOS interrupt 0x16 to read keyboard input. The monitor reads the input, waits for three consecutive digits from 0 to 7 to be input, translates them into hex and stores them in memory. If it detects anything different from these 8 digits, it just jumps to the program we've input so far, and executes it.
Why 3-digit numbers? Well, with 3 digits in octal we can represent 2 digits in hex (0o377 = 0xFF), which are 8 bits in binary (0xFF = 0b11111111). And so, once we have 3 digits in octal, that means we have a 1 byte number (as long as the octal number is <= 0o377), which we can go ahead and store into memory as the next byte. Let's look at an example. If we input the number 020 into the monitor, this will be translated to the hex byte 0x10. Do you know what that byte means? We've seen it before - it's the BIOS interrupt for printing onto the screen!
So, not only can we put random numbers into our monitor, that may or may not mean anything, we can input opcodes, BIOS interrupts and variables into it, constructing machine code that the computer can just run. We've gone to the lowest of low levels! We aren't even writing assembly anymore, we are literally speaking CPU-ese now.
Now, I've gone through the trouble of translating our Wilson program into octal machine code for us to use. It's just short enough, so we can test our monitor with it:
264 016 260 110 315 020 264 016 260 151 315 020 364
All we have to do now is put our monitor on a floppy, start our PC with it inserted, wait for the BIOS to load the monitor (and display nothing), blindly input the machine code from above (without spaces!), hit a key which is larger than 7, and see if we can revive Wilson!
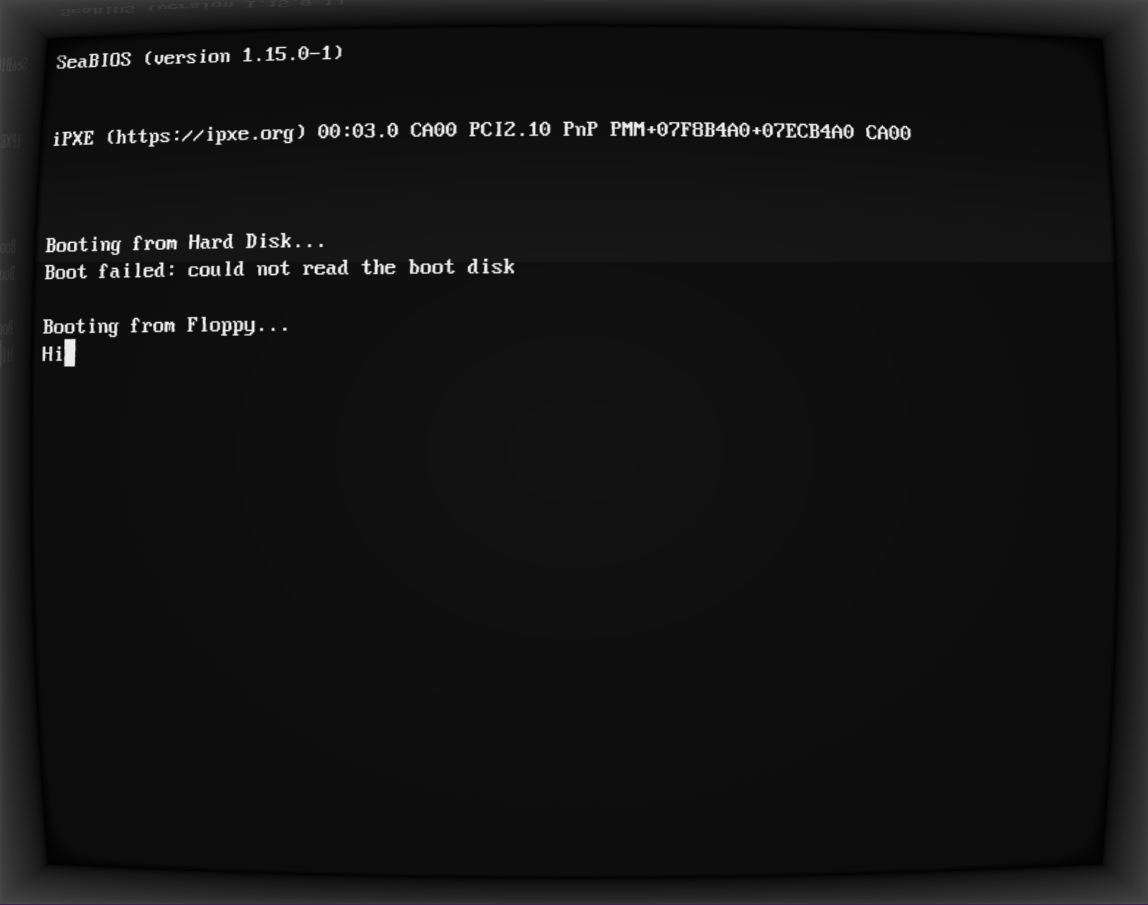
I mean, at this point you really have to trust me that I did this...or go and do it yourself, using the code in the repo.
So far - so good
In an extremely minimalistic way, we've technically achieved the requirements of the thought experiment. We have now a monitor program, which boots from the boot sector of a floppy disk, and in which we can input machine code to be executed directly from memory.
The next step would be to write a better monitor program, which has more text-editing capabilities. Then, maybe write a small assembler, so that we can write assembly instead of machine code, and assemble and run it. At that point, we will probably want to also escape real-mode, and go into 32-bit protected mode. Then we can even start writing and compiling C! And then we're really off to the races.
But let's just take a minute to appreciate what we've achieved. We do technically have the first step towards bootstrapping an entire computer from BIOS! If we are patient and damn-stubborn enough, we can build an OS from this by never leaving Wilson's keyboard again!
I will do all of these steps, and more, but for the time being I will leave this as is, so it doesn't become too cumbersome to read. I'm going to continue posting on the subject, so keep an eye out! Meanwhile, I hope you've enjoyed the ride so far, and are looking forward to more Bootstrapping from BIOS shenanigans! Have fun!