
Reading is an integral part of writing.
There are many ways this statement can be phrased, but it carries the message accross. Before creating something new and original, we need to have information in the context of the thing we're trying to create.
And all of that starts with research.
When I start researching a subject, I begin by googling something, which then turns into dozens of open tabs in the browser.
I'm too afraid to close any of the tabs, lest I forget something.
When I look at information I've stored, I no longer remember why I thought this was important, or how it connects to what I was searching for.
Do these sound familiar to you? I can't imagine I'm the only one facing these problems.
Creating a linear output out of non-linear input
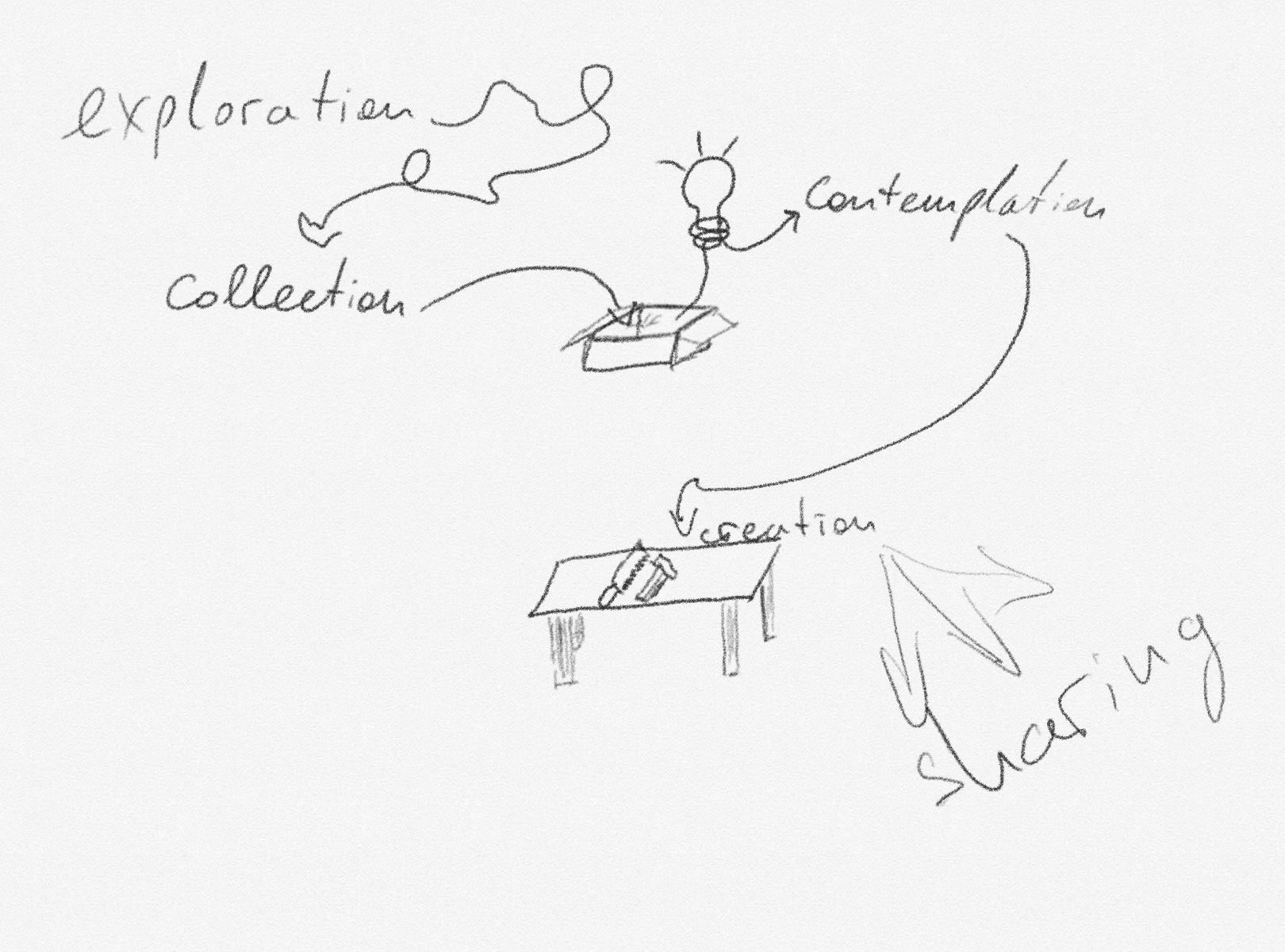
The thing that allowed me to think about the importance of contextualising knowledge, is the discovery of the knowledge management lifecycle. I've since seen many different versions of this thing, but the one that resonated with me was the following:
exploration -> collection -> contemplation -> creation -> sharing.
The reason this particular scheme spoke to me, was the distinction between exploration and collection. In a typical for me scenario, when I set out to learn about something, I start by searching on Google, trying to get into a rabbit hole of knowledge gathering. This is the exploration phase of the above. But try and imagine how you jump from exploration to the thinking phase - contemplation.
After a successful search hunt, you now have let's say 20 tabs open in your browser. Some of them barely touch on the subject matter of interest, some of them have golden nuggets in there, and some you thought you'd read into later. Then a day passes, with the browser open, and you already don't remember what you wanted to read or take note of. And your "collection" is so ephemeral, that any closed tab could remove context from 10 other tabs. Imagine now that you have to stop thinking about this particular subject for a week, or longer...
In reality, we've touched upon the subject of non-linearity of the creation process. The process of creation is that of connecting preexisting information into a coherent, mostly linear output, with the occasional sidenote. But the information you're working with is itself messy: a complicated graph of intertwining lines connecting dots in your brain. It's multidimensional and non-linear.
And the exploration, collection, and even creation phase of the lifecycle are depicting exactly this phase of non-linearity of the process.
But moreover, your brain is not as good at remembering as a computer harddrive is.
Tracing the discovery context
"Well, obviously the solution to all of this is note-taking", I hear you say at the back of my head. And in a sense, you're right. But what would you write in those notes? Are your notes going to be any different from saving all of your open tabs in a folder in Notion? What happens when in a month you open up your Notion, and go to the folder consisting of 30 URLs. Do you still remember what was what in there? I definitely don't, but if you do, all the power to you.
This is where I started thinking of knowledge laid out in a graph in front of me, a map if you will. This is definitely not a unique idea, and some note-taking apps like Obsidian and RoamResearch already allow you to do this in certain ways. This is the idea of interconnecting different nuggets of information by linking between them - in a forwards and backwards direction.
And the backward direction is the crux of the problem. Opening 30 tabs in your browser, or saving 30 URLs in a text file, doesn't have one thing in particular - backlinks. Compiling a list of articles is not self-referential by design. It's a divergent thought process, or at best a linear read.
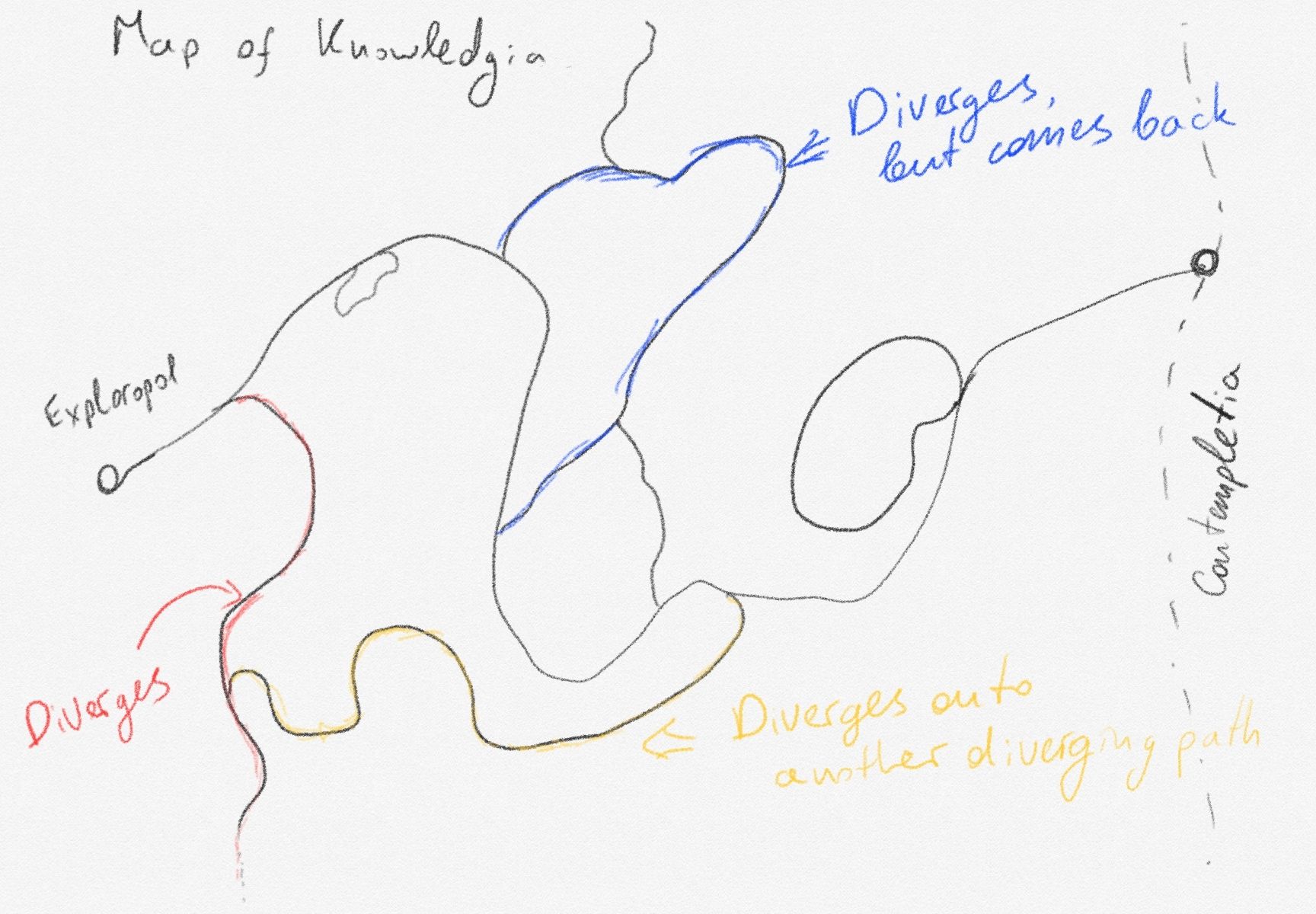
Let me give you a thought experiment. Have you even been on Wikipedia? A typical exploration phase on Wikipedia goes as follows - you search for an article on it, and start reading it. In the text you find something you need to know more about, so you click on the little blue text to learn more. On the new article, you do the same. And after a while, you're deep in a rabbit hole, gasping for air, your head pounding from the sounds of collapsing walls of dirt around you. And you don't even remember where you started from. Not that it doesn't feel good to learn so many new things, but you've completely diverged from your original research goal.
But what if instead, on the 5th article you went down to, you found a link to the original article you opened Wikipedia for? That would be awesome! You have now completed your first contextual circle! The rabbit hole just circled you back to your original path. You have validated your research, learned quite a few new things, and have returned to where you left off, able to continue on your merry path to enlightenment.
Also, the probability of this happening while researching on Google is close to none.
Conclusion
The lack of stored context in the exploration phase is what makes it impossible to remember the relevant information during the collection or creation phases. No context means no way to connect separate information nuggets to a given concept, idea or subject. The brain simply dismisses it as irrelevant, and slowly gets rid of the memory.
Sadly, your typical browser interface doesn't really allow for visualising these complex non-linear interactions in lines of thought. This problem of the world-wide Web is something I believe Douglas Engelbart was fully aware of, and was unhappy about. But sadly it's a fundamental issue. I would love to get deeper into it, and even look for a solution. But to my knowledge, the only realistic way to avoid this decontextualised thought pattern in online research is manually creating a knowledge map of your own research.
And the manual solution reads something like this:
- During the exporation phase, don't worry about going down rabbit holes, but keep track of the context in which you discover information. The browser history might be useless in this scenario, but storing links with short descriptions or with the relevant search terms might be a useful manual step.
- In the collection phase, take notes by having in mind the graphical representation of your knowledge. Your research can lead you to the following lines of thought:
- diverge from the core subject, and never come back
- diverge and wrap around to the core line of thought
- diverge and join in with another divergent line of thought (could still be useful in the context of serendepity)
As far as tools are concerned, you can discover what works best for you, but I recommend a note-taking tool which can create graphs of your knowledge map. It's so much better, when you can create an overview of interconnecting nuggets of knowledge, and see the context from a bird's perspective.
Having different information nuggets stored in an app also allows for their reuse, facilitating contextual serendipity. A concept I would like to discuss further as well.
Thank you for reading!
The information in this blog, as well as all the tools, apps and libraries I develop are currently open source.
I would love to keep it this way, and you can help!
You can buy me a coffee from here, which will go towards the next all-nighter I pull off!

Or you can support me and my code monthly over at Github Sponsors!
Thanks!